
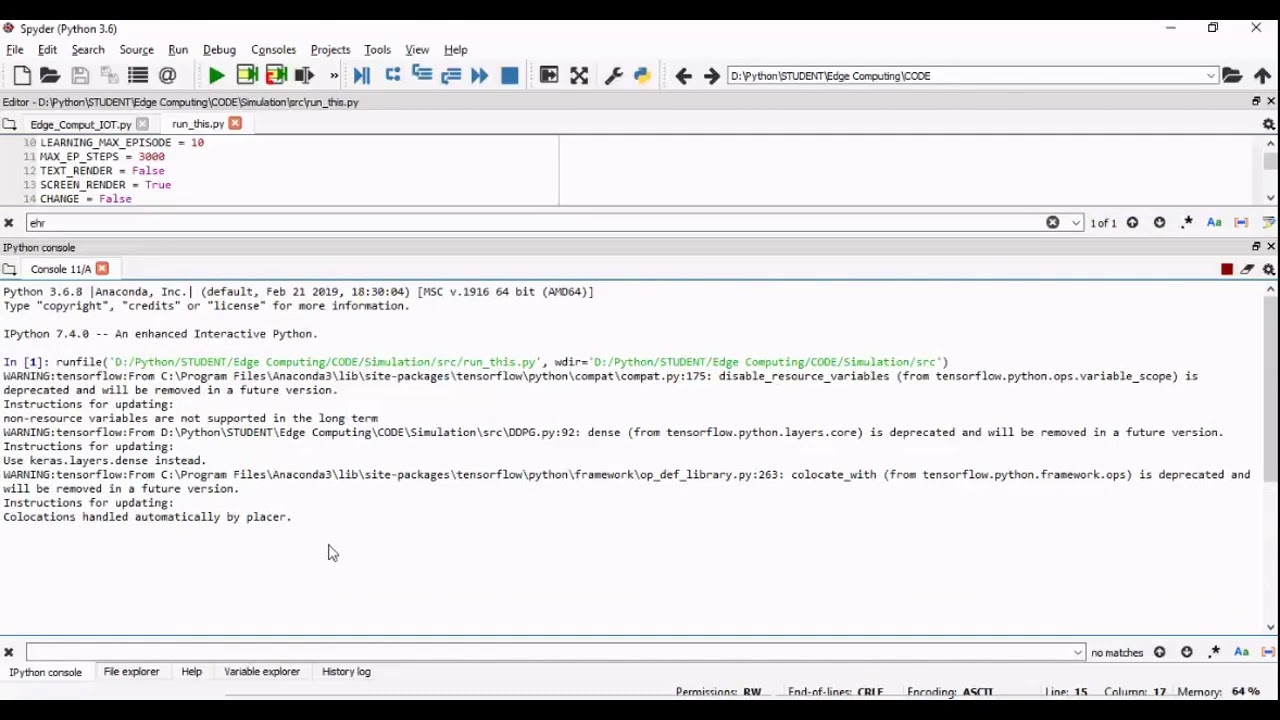







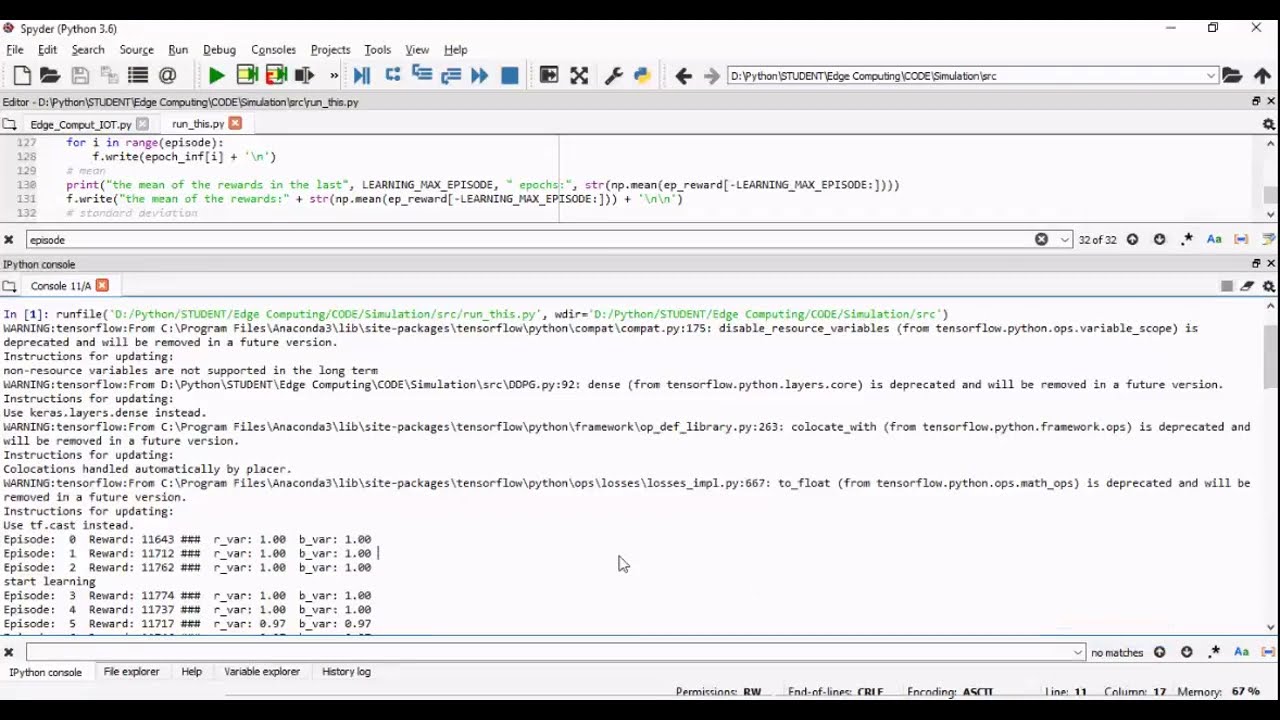
Security and Energy Harvesting for MIMO OFDM Networks
Security and Energy Harvesting for MIMO OFDM Networks
Time Domain Channel Estimation for MIMO‑FBMC OQAM Systems
Time Domain Channel Estimation for MIMO‑FBMC OQAM Systems



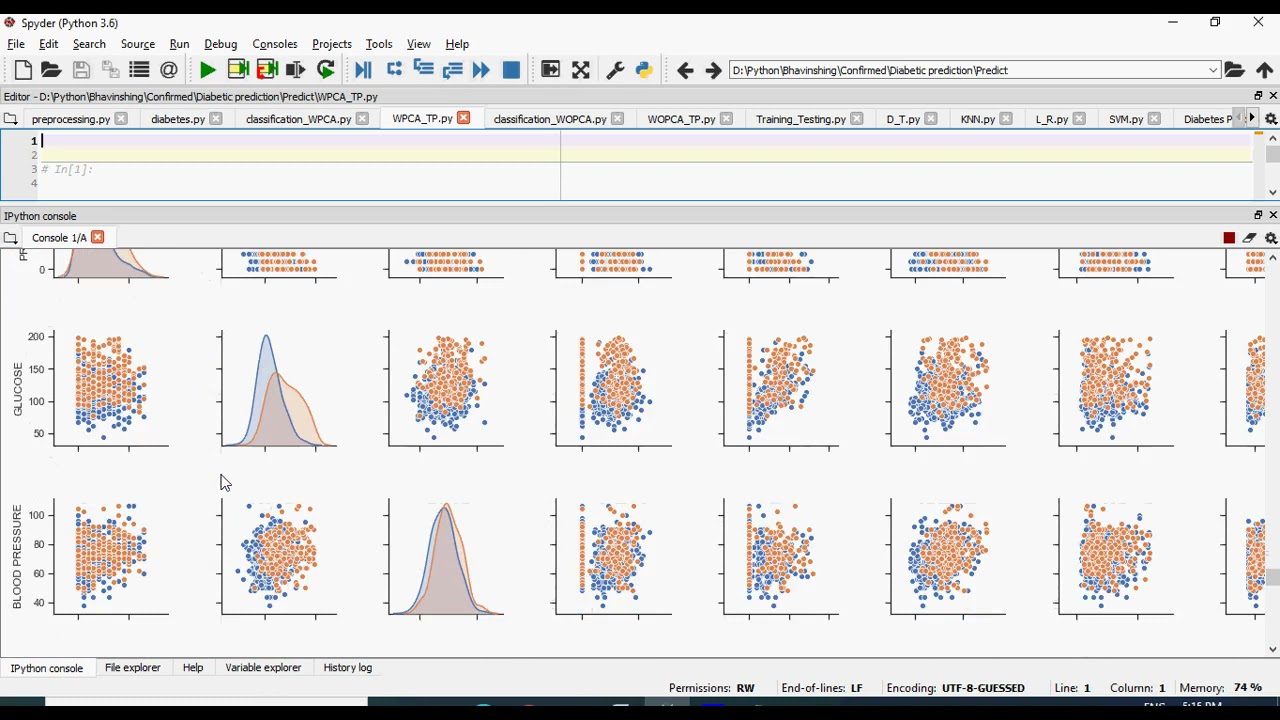












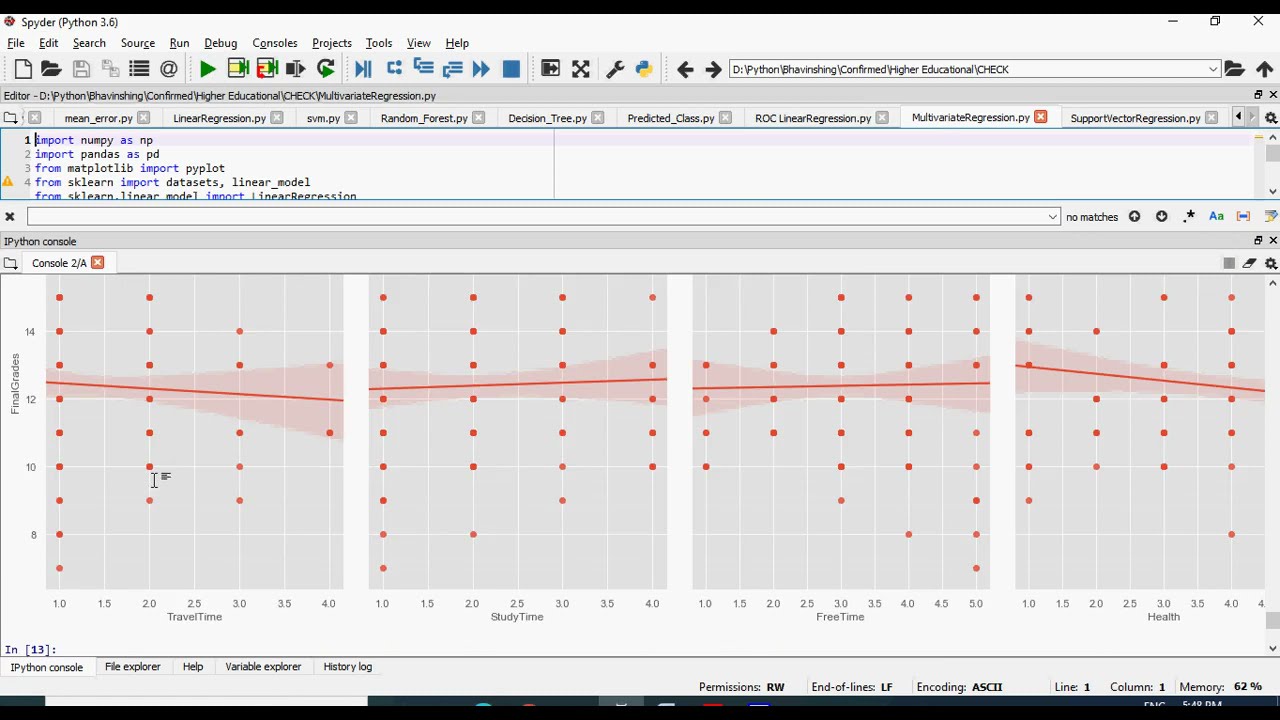
Security and Energy Harvesting for MIMO OFDM Networks
Time Domain Channel Estimation for MIMO‑FBMC OQAM Systems

Spectrum Sharing in mmWave Cellular Networks Using Clustering Algorithms in Java
Robust Loss Inference in the Presence of Noisy Measurements and Hidden Fault Dia...
Social Aware Privacy Preserving Mechanism for Correlated Data in Java
Shuffle Scheduling for MapReduce Jobs Based on Periodic Network Status in Java
Risk Aware Data Offloading in Multi Server Multi Access Edge Computing Environme...
Efficient Secure Outsourcing of Large Scale Sparse Linear Systems of Equations i...
Dynamics of Public Opinions in an Online and Offline Social Network in Hadoop Bi...
Developer Play Console Gandhipuram Coimbatore IEEE Projects Gandhipuram Coimbatore
Developer Play Console Gandhipuram Coimbatore IEEE Projects Gandhipuram Coimbatore
Efficient Traffic Offloading Vertical Handover Algorithm for Heterogeneous Wirel...
Riding the Data Tsunami in the Cloud Myths and Challenges in Future Wireless Acc...
Video Stream Analysis in Clouds An Object Detection And Classification Framework...

Machine Learning Dan Artificial Intelligence Peelamedu Coimbatore IEEE Projects Peelamedu Coimbatore
Projects in Btech Peelamedu Coimbatore Student Projects Peelamedu Coimbatore
Thesis for Mtech Peelamedu Coimbatore Final Year Projects Peelamedu Coimbatore
Project Mcom Peelamedu Coimbatore IEEE Projects Peelamedu Coimbatore
Big Data Dan Cloud Computing Peelamedu Coimbatore Student Projects Peelamedu Coimbatore
B Tech Projects On Machine Learning Peelamedu Coimbatore Final Year Projects Peelamedu Coimbatore
Mini Project for B Tech Computer Science Peelamedu Coimbatore IEEE Projects Peelamedu Coimbatore
Btech Computer Science Project Ideas Peelamedu Coimbatore Student Projects Peelamedu Coimbatore
Cloud Year Peelamedu Coimbatore Final Year Projects Peelamedu Coimbatore
Google Play Card Srbija Peelamedu Coimbatore IEEE Projects Peelamedu Coimbatore
Mtech Final Year Project Peelamedu Coimbatore Student Projects Peelamedu Coimbatore
Dotnet Projects for Final Year Students Peelamedu Coimbatore Final Year Projects Peelamedu Coimbatore
